


明略科技即将开源Blockformer语音识别模型,提升销售过程中的会话智能并助力各行业数智化转型
深度学习已成功应用于语音识别,各种神经网络被大家广泛研究和探索,例如,深度神经网络(Deep Neural Network,DNN)、卷积神经网络(Convolutional Neural Network,CNN)、循环神经网络(Recurrent Neural Network,RNN)和端到端的神经网络模型。
目前,主要有三种端到端的模型框架:神经网络传感器(Neural Transducer,NT),基于注意力的编码器-解码器(Attention-based Encoder Decoder,AED)和连接时序分类(Connectionist Temporal Classification,CTC)。
NT是CTC的增强版本,引入了预测网络模块,可类比传统语音识别框架中的语言模型,解码器需要把先前预测的历史作为上下文输入。NT训练不稳定,需要更多内存,这可能会限制训练速度。
AED由编码器、解码器和注意力机制模块组成,前者对声学特征进行编码,解码器生成句子,注意力机制用来对齐编码器输入特征和解码状态。业内不少ASR系统架构基于AED。然而,AED模型逐个单元输出,其中每个单元既取决于先前生成的结果,又依赖后续的上下文,这会导致识别延迟。
另外,在实际的语音识别任务中,AED的注意力机制的对齐效果,有时也会被噪声破坏。
CTC的解码速度比AED快,但是由于输出单元之间的条件独立性和缺乏语言模型的约束,其识别率有提升空间。
目前有一些关于融合AED和CTC两种框架的研究,基于编码器共享的多任务学习,使用CTC和AED目标同时训练。在模型结构上,Transformer已经在机器翻译,语音识别,和计算机视觉领域显示了极大的优势。
明略科技集团高级总监、语音技术负责人朱会峰介绍,明略团队重点研究了在CTC和AED融合训练框架下,如何使用Transformer模型来提高识别效果。

明略团队通过可视化分析了不同BLOCK和HEAD之间的注意力信息,这些信息的多样性是非常有帮助的,编码器和解码器中每个BLOCK的输出信息并不完全包含,也可能是互补的。(https://doi.org/10.48550/arXiv.2207.11697)
基于这种洞察,明略团队提出了一种模型结构,Block-augmented Transformer (BlockFormer),研究了如何以参数化的方式互补融合每个块的基本信息,实现了Weighted Sum of the Blocks Output(Base-WSBO)和Squeeze-and-Excitation module to WSBO(SE-WSBO)两种block集成方法。

Blockfomer with Base-WSBO

SE-WSBO
实验证明,Blockformer模型在中文普通话测试集(AISHELL-1)上,不使用语言模型的情况下实现了4.35%的CER,使用语言模型时达到了4.10%的CER。

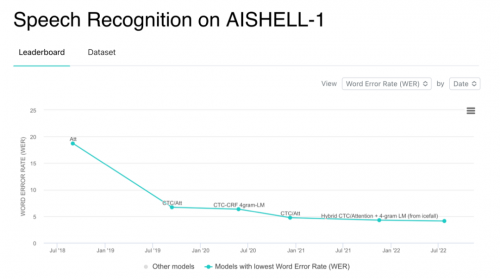

AISHELL-1是希尔贝壳2017年开源的中文普通话语音数据库,录音时长178小时,由400名中国不同地域说话人进行录制。该数据库涉及智能家居、无人驾驶、工业生产等11个领域,被高频应用在语音技术开发及实验中,是当今中文语音识别评测的权威数据库之一。
AI Wiki网站Papers With Code显示,Blockformer在AISHELL-1上取得SOTA的识别效果,字错率降低到4.10%(使用语言模型时)。
明略科技集团CTO郝杰表示,明略的会话智能产品针对基于线上企微会话和线下门店会话的销售场景,语音识别团队聚焦美妆、汽车、教育等行业的场景优化和定制训练,但是也不放松对通用语音识别新框架、新模型的探索,Blockformer模型的这个SOTA效果为语音识别的定制优化提供了一个高起点,明略即将开源Blockformer。
(来源:新视线)












