


随着大模型技术迎来颠覆性突破,新兴AI应用大量涌现,不断重塑着人类、机器与智能的关系。
为此,昆仑万维天工团队重磅推出「天工一刻」系列内容,对大模型上下游技术进行一次全面解读,涵盖学术热点、技术创新、应用案例等。希望我们的内容能为所有关注大模型技术的读者,提供一些借鉴与参考。
向量数据库火了。
去年年初,大模型火遍全球,作为核心相关技术的向量数据库热度也持续走高,Pinecone、Weaviate、Chroma、Qdrant、Fabarta等创业项目陆续宣布数千万、甚至上亿美元的大额融资;行业知名玩家Zilliz关注度一飞冲天;开源项目如Milvus、Vald等动作频频;AWS、谷歌云、阿里云、腾讯云等云计算大厂们也争相升级产品。
根据东北证券计算,2030年,全球向量数据库市场规模有望达到500亿美元,国内向量数据库市场规模有望超过600亿人民币。
其实,向量数据库是个老牌技术,并不是在大模型走红之后才诞生,但因其与大模型技术的高度适配性而受到业内强烈热捧,加之行业巨头英伟达和OpenAI都曾“点名表扬”向量数据库技术,在这场大火中又添了一把柴。
阅读本文,你将得到以下问题的答案:
向量数据库是什么,它凭什么这么火?
向量数据库跟大模型有什么关系?
看懂哪些参数,才能看懂向量数据库?
一、“万物皆可Embedding”
要理解向量数据库(Vector Database),首先要理解向量(Vector)的概念。
向量指具有大小和方向的量,它在直角坐标系里通常表现为一段带箭头的线段。
 (向量指具有大小和方向的量,图片来自byjus)
(向量指具有大小和方向的量,图片来自byjus)这个概念似乎很简单,大家数学课上都学过。
然而,就是“向量”这么个简单的概念,竟然以一己之力撑起了当代整个AI学科。神经网络跟大模型来了都得叫它一声“祖宗”。
这是因为,向量的概念看似简单,但它的引申能力“向量化(Embedding)”却不简单。
向量化,指的就是将其他类型的信息转换为向量。
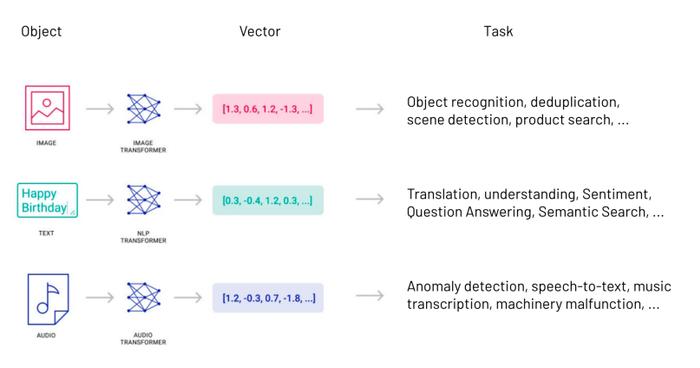 (将不同类型的信息用向量进行表达,图片来自Pinecone)
(将不同类型的信息用向量进行表达,图片来自Pinecone)由于向量可以高度抽象地表示事物的特征和属性,世界上几乎所有类型的数据——视频、图像、声音、文本……统统都可以通过数据处理转换成向量。
例如,在自然语言中, 不同的词句可以用不同的向量表示;在计算机视觉中,不同的图像也能够被表示成不同的向量。
因而,在计算机领域流传着一句话,“万物皆可Embedding。”
有人要问了,把数据向量化之后呢?
此时你会发现,神奇的事情发生了——向量跟向量之间,是可以运算的。
你无法对两张图片、两段语音进行运算,但是,你可以对这代表这段数据的向量进行运算、处理、进而衍生出更多可能性。
是的,从人脸识别到语音识别,从GPT到AI搜索,当前,几乎所有AI运算,都通过向量运算来实现。
无论是上一拨以计算机视觉为首的CNN卷积神经网络、还是这一拨以大模型为首的Transformer算法,其计算的本质都是对向量进行处理和变化。
尤其是大模型,其Transformer架构本身的Encoder-Decoder(编码-解码)模块设计简直是为向量数据“量身定做”的。
说它以一己之力撑起当代整个AI学科,并不夸张。
二、传统数据库 vs 向量数据库
数据库技术已有近半个世纪的发展历史,是计算机领域的核心底层技术之一。
传统数据库主要用于存储与管理具有明确定义和固定格式的结构化数据,比如A股十年间的数值变化、同一时间中国各地的地表温度、一个人在一年之内的体重变化等等。
然而,随着人类科技的不断进步,近年来,非结构化数据逐渐登上了历史舞台。
图像、声音、视频、语言……这些都是难以用结构化信息所表达的非结构化数据。而是否能理解它们,成为了衡量机器智能程度的标杆。
向量数据库则属于新型数据库技术,专注于向量数据的存储与管理,并能进行向量搜索、相似度查询等功能。
通过向量化技术,大量非结构化数据能够转化为向量,从而通过向量数据库技术实现高效的存储与管理,让无数AI应用得以落地。
拿人脸识别举例。
假设你拍摄了一张100万像素的彩色人脸图片,在传统数据库中,它理论上由100万个像素点组成,每个像素点又需要由R、G、B、A这4组数据表示,所以仅仅是一张图片,就需要有4x100万=400万个数据。
现在,数据库里有1万张人脸的照片,请进行比较,最符合的是哪一张照片?
由于传统数据库通常只能判断YES/NO,也就是1=1,1≠3。想象一下,如果在传统数据库中直接进行“暴力”检索,400万x1万这种上百亿级别的计算量会直接让系统算到地老天荒。
更困难的是,明明只是同一个人在不同光线下的照片,人类一眼就看得出来,电脑却会因为光照、视拍照角等微小差异而返回“匹配失败”。
然而,如果你把这些照片变成向量,神奇的事情发生了。
还记得吧?向量跟向量之间,是可以直接运算的。
欧式距离、余弦、内积、海明距离……通过计算两个向量之间的距离(相似度),就可以直接找到跟它最接近的一个到多个不等的结果。
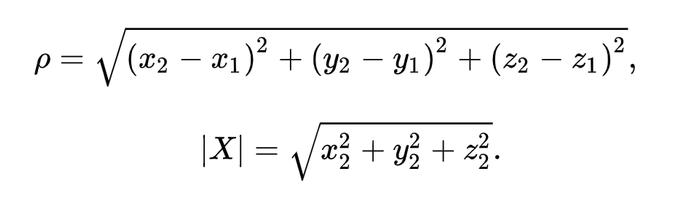 (向量在三维空间的欧式距离计算公式)
(向量在三维空间的欧式距离计算公式)这可是实打实“降维打击”,不仅计算难度指数级下降,而且还可以开发出向量检索、向量聚类、甚至是将数据库中的高维向量转换成低维向量这类向量压缩与降维的“黑科技”。
再加上“万物皆可Embedding”的基础上,一段音频、一张图片、一段视频都能够用向量表达,使得向量数据库天生自带多模态基因,以图搜图等一众多模态应用不在话下。
更大的数据容量、更快的检索与分析、更强的跨模态能力、更极端的高并发需求……种种能力加持之下,让向量数据库在人工智能时代——尤其是大模型时代——一举跃升为最重要的底层技术之一。
三、“大模型的海马体”
论起来,向量数据库是大模型的“前辈”,它比大模型出现得要早得多。然而,它在2023年才因大模型而“走红”。
这其实是一场向量数据库与大模型的“双向奔赴”。
对于大模型而言,向量数据库不仅能使得模型训练异常高效,还能够解决不少大模型现实应用中所遇到的困难;对于向量数据库而言,大模型能够让其技术优势得以充分发挥,其现象级的传播性更是堪称向量数据库的杀手级应用。
向量数据库与大模型的高度适配,首先体现在原生性上。
正如上文所言,大模型AI计算的核心就是向量的处理与变化。大模型在前期训练阶段,需要将海量的非结构化数据(文本、图片、音频、视频)进行向量化,才能够开始真正的训练过程。向量数据库的向量原生性能够显著地为大模型训练进行降本增效。
其次,为了让用户更好理解,行业内常常将大模型比喻为人类的大脑,向量数据库则在其中扮演着“海马体”的作用。海马体是组成大脑边缘系统的一部分,主要负责学习和记忆。
一方面,向量数据库能够储存“记忆”——即数据。大模型某种程度相当于大脑的CPU,如果把所有数据都存到CPU里,日常计算的参数规模就会巨大无比,计算效率极慢。
向量数据库在此时扮演了“片外存储”的角色,CPU运算过程中可以随时到向量数据库里面来取数据,让模型可以高效运转。
另一方面,就是大模型预训练数据的“老旧”。
经常使用大模型的用户多少都曾遇到过这样的痛点——大模型预训练的数据老旧、或者缺少某部分专业知识,无法很好地完成当前任务。
比如,ChatGPT目前的预训练数据更新截止至2021年9月,这也就意味着最近2年内发生的事情它都“不知道”。
解决办法可以是对“大脑”进行“手术”,通过对模型的微调(Fine-tune)设计一个更符合需求的新大脑。但很显然,这个方案成本极高。
此时,用向量数据库给大模型更新数据,则相当于不对大脑动手术,而是让大脑看一本新书,以更低的成本获得更新、更专业的知识内容,突破大模型预训练数据的老旧性带来的限制。
最后,在大模型的实际应用中,向量数据库还可以一定程度解决备受企业关注的数据隐私问题。
在企业运营决策过程中,将会涉及大量需要重点保密的私有数据。让每个企业都拿这些数据来单独训练自己专用的大模型显然不现实,但是不能使用这些数据又会让大模型技术难以真正融入企业工作流程。
此时,通过大模型“外接”向量数据库,就能既保证了企业数据的隐私和安全,又能让大模型在企业应用场景中更好地发挥作用。
四、如何看懂向量数据库
了解了向量数据库的概念,接下来就是如何“看懂”向量数据库。
向量数据库的核心技术包括数据向量化(Embedding)、向量索引/向量检索、存储、计算、硬件加速等等。
而向量数据库的衡量标准有两大类,性能指标和效果指标。
说起来很复杂,但从本质上来讲,向量数据库核心要解决的就是两件事:在海量的数据存储中,如何进行高效的检索。
拆分下来就是向量数据库的文档规模要大、检索响应要快、召回率要高、准确率要高。
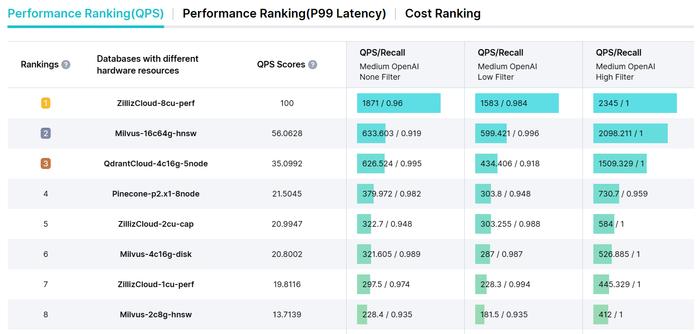 (VectorDBBench向量数据库性能评估工具)
(VectorDBBench向量数据库性能评估工具)1. 文档规模
衡量一个向量数据库,一个最直观的参数就是文档规模。
举个例子,目前业内大多数头部的开源/非开源向量数据库都能做到十亿级以上的检索规模,少数能够支持百亿级别。
由于向量数据库的文档规模跟具体业务场景关系密切,倒不是说必须越大越好;但在如AI搜索这类百亿级以上的文档规模应用时,如何平衡文档规模与索引速度就成了难题。
2. QPS每秒响应请求数
在向量数据库中,QPS(Queries Per Second,每秒响应请求数)是衡量数据库在一秒钟内接收响应数量的大小,翻译过来就是每秒能干多少活。
理论上这一数值越高越好,尤其是在大规模的高性能、高并发、高可用的“三高”场景中。根据VectorDBBench数据,目前这项参数业内顶尖的表现达到了822.5,第二名为303.2。
3. 召回率和准确率
正如在天工一刻AI搜索技术篇中所言《天工一刻 | 跨语言检索、检索增强生成……一文看懂最火大模型AI搜索技术》。召回指的是从数据库的全量信息集合中触发尽可能多的正确结果,并将结果返回。
向量数据库的召回率和准确率是一对需要兼顾与平衡的指标,它需要如大海捞针一般,在百亿级别的文档里最准确地找到最相关的数篇文档。根据VectorDBBench数据,目前这项参数业内顶尖的表现均为0.9以上。
4. Load_duration数据加载耗时与Serial_latency延时
数据加载耗时与延时都很好理解,就是一个字,快。
就像上文所说,在百亿级的文档中找目标有如大海捞针。如果对这个数量级没概念的话,打个比方——假设你每1秒能看完10篇文档,那么将100亿份文档全部看完,需要11574天,超过31年的时间。
如果找10篇文档需要31年,显然是不能满足需求的。向量数据库要求数据加载耗时和系统延时越小越好,根据VectorDBBench数据,目前这两项参数业内顶尖的表现分别为5714s与5.6ms。
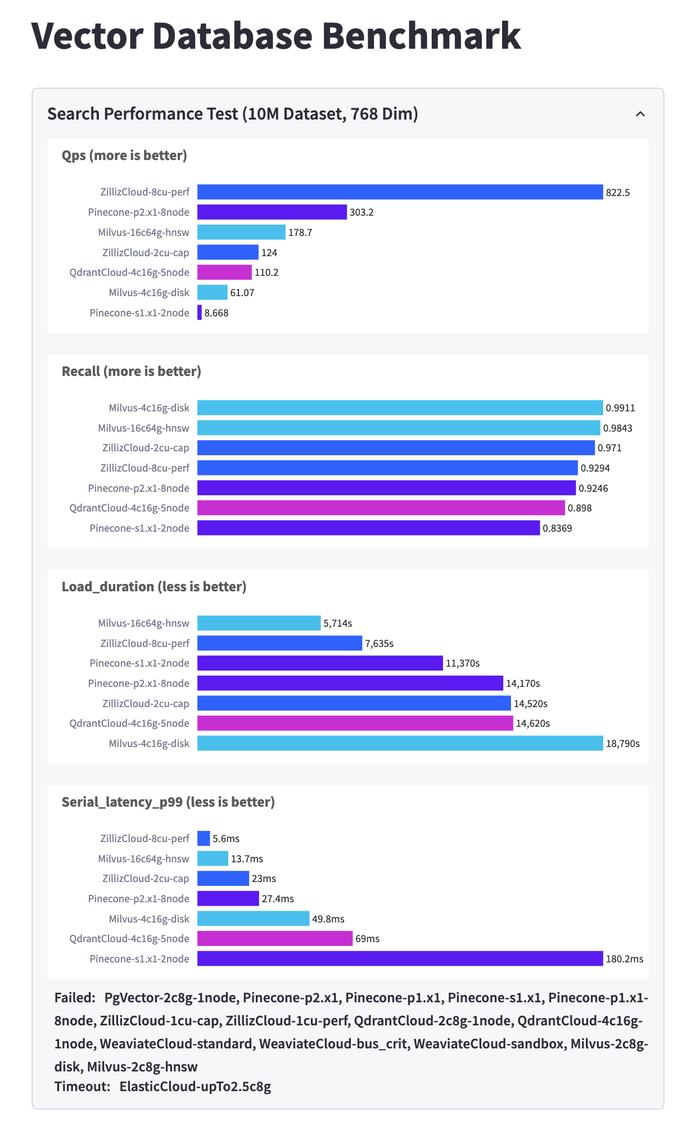 (VectorDBBench向量数据库性能评估结果)
(VectorDBBench向量数据库性能评估结果)随着人工智能时代兴盛,图像、视频、音乐等大量非结构化数据爆发,卷积神经网络、大语言模型以及更多的新兴技术出现,让向量数据库的重要性日益凸显。
随着人工智能数据量越来越大,传统的关系型数据库已经无法满足新时代需求,尤其是自大模型火遍全球以来,向量数据库的热度也持续走高,一跃成为当前最火的技术赛道之一。
(来源:News快报)












